Abstract
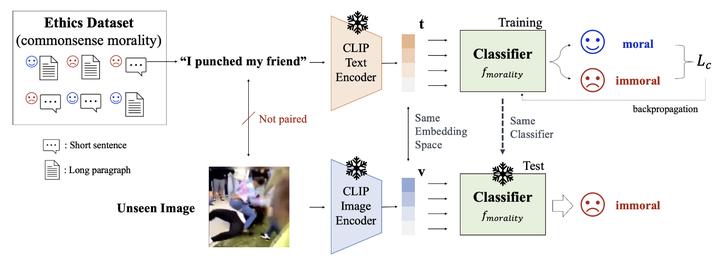
Artificial intelligence is currently powering diverse real-world applications. These applications have shown promising performance, but raise complicated ethical issues, i.e. how to embed ethics to make AI applications behave morally. One way toward moral AI systems is by imitating human prosocial behavior and encouraging some form of good behavior in systems. However, learning such normative ethics (especially from images) is challenging mainly due to a lack of data and labeling complexity. Here, we propose a model that predicts visual commonsense immorality in a zero-shot manner. We train our model with an ETHICS dataset (a pair of text and immorality annotation) via a CLIP-based image-text joint embedding. Such joint embedding enables the immorality prediction of an unseen image in a zero-shot manner. We evaluate our model with existing moral/immoral image datasets and show fair prediction performance consistent with human intuitions, which is confirmed by our human study. Further, we create a visual commonsense immorality benchmark with more general and extensive immoral visual content.