BMWReg: Brownian-diffusive, Multiview, Whitening Regulararizations for Self-supervised Learning
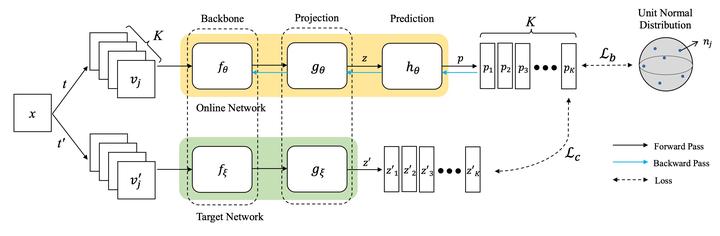 Image credit: Unsplash
Image credit: Unsplash
Abstract
Recent self-supervised representation learning methods depend on joint embedding learning with siamese-like networks, trained by maximizing the agreement of differently augmented same-class representations (positive pairs). Using positive pairs may avoid dealing with computationally demanding negatives, but so-called mode collapse may occur without any implicit biases in the learning architecture. In this paper, we propose a new loss function, called BMWReg, which induces an implicit contrastive effect in the embedding space, effectively preventing a mode collapse. BMWReg consists of the following three regularization terms. (i) a Brownian diffusive loss, which induces a Brownian motion in the embedding space so that embeddings are uniformly distributed on the unit hypersphere. (ii) A multi-view centroid loss, which applies an attractive force to pull together multiple augmented representations of the same image into the geometric centroid. (iii) A whitening loss, which decorrelates the different feature dimensions in the latent space. We evaluate BMWReg on two visual benchmarks – ImageNet-100 and STL-10. In addition, we also show that applying our regularization term to other methods further improves their performance and stabilize the training by preventing a mode collapse.
Supplementary notes can be added here, including code, math, and images.