 Image credit: Kim et al., RA-L 2021
Image credit: Kim et al., RA-L 2021
Abstract
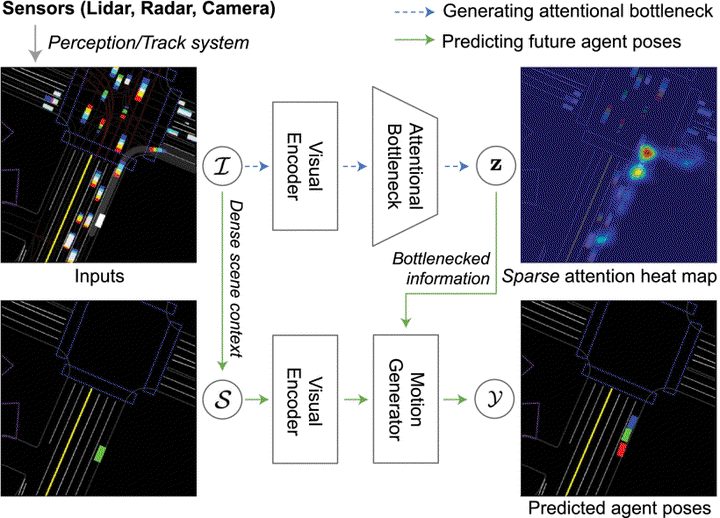
Deep neural networks are a key component of behavior prediction and motion generation for self-driving cars. One of their main drawbacks is a lack of transparency – they should provide easy to interpret rationales for what triggers certain behaviors. We propose an architecture called Attentional Bottleneck with the goal of improving transparency. Our key idea is to combine visual attention, which identifies what aspects of the input the model is using, with an information bottleneck that enables the model to only use aspects of the input which are important. This not only provides sparse and interpretable attention maps (e.g. focusing only on specific vehicles in the scene), but it adds this transparency at no cost to model accuracy. In fact, we find improvements in accuracy when applying Attentional Bottleneck to the ChauffeurNet model, whereas we find that the accuracy deteriorates with a traditional visual attention model.