VITA-PAR: Visual and Textual Attribute Alignment with Attribute Prompting for Pedestrian Attribute Recognition
Abstract
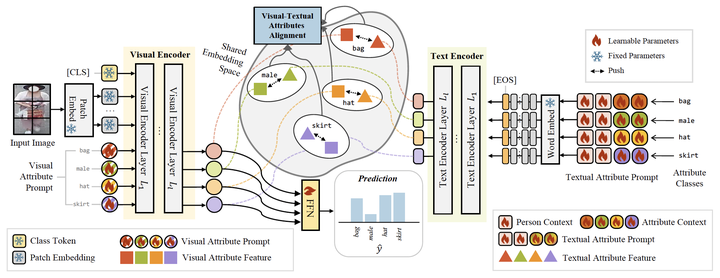
The Pedestrian Attribute Recognition (PAR) task aims to identify various detailed attributes of an individual, such as clothing, accessories, and gender. To enhance PAR performance, a model must capture features ranging from coarse-grained global attributes (e.g., for identifying gender) to fine-grained local details (e.g., for recognizing accessories) that may appear in diverse regions. Recent research suggests that body part representation can enhance the model’s robustness and accuracy, but these methods are often restricted to attribute classes within fixed horizontal regions, leading to degraded performance when attributes appear in varying or unexpected body locations. In this paper, we propose Visual and Textual Attribute Alignment with Attribute Prompting for Pedestrian Attribute Recognition, dubbed as ViTA-PAR, to enhance attribute recognition through specialized multimodal prompting and vision-language alignment. We introduce visual attribute prompts that capture global-to-local semantics, enabling diverse attribute representations. To enrich textual embeddings, we design a learnable prompt template, termed person and attribute context prompting, to learn person and attributes context. Finally, we align visual and textual attribute features for effective fusion. ViTA-PAR is validated on four PAR benchmarks, achieving competitive performance with efficient inference.