Abstract
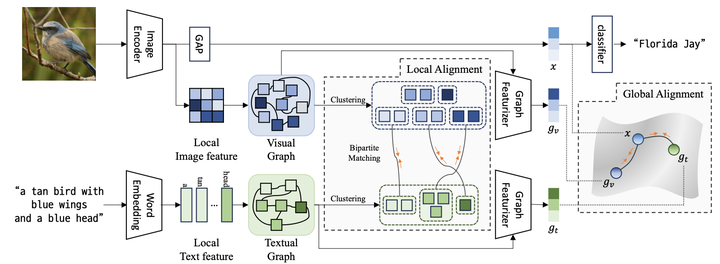
Learning domain-invariant representations is important to train a model that can generalize well to unseen target task domains. Text descriptions inherently contain semantic structures of concepts and such auxiliary semantic cues can be used as effective pivot embedding for domain generalization problems. Here, we use multimodal graph representations, fusing images and text, to get domain-invariant pivot embeddings by considering the inherent semantic structure between local images and text descriptors. Specifically, we aim to learn domain-invariant features by (i) representing the image and text descriptions with graphs, and by (ii) clustering and matching the graph-based image node features into textual graphs simultaneously. We experiment with large-scale public datasets, such as CUB-DG and DomainBed, and our model achieves matched or better state-of-the-art performance on these datasets. Our code will be publicly available upon publication.