Abstract
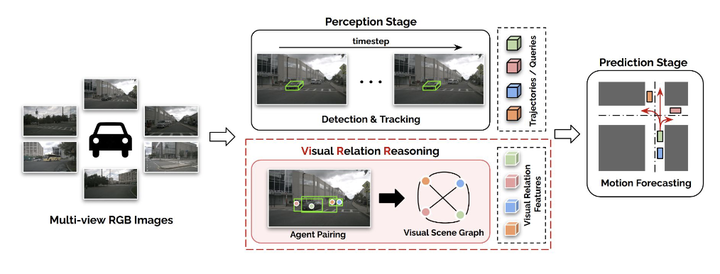
In this work, we emphasize and demonstrate the importance of visual relation learning for motion forecasting task in autonomous driving (AD). Since exploiting the benefits of RGB images in the existing vision-based joint perception and prediction (PnP) networks is limited in the perception stage, we delve into how the explicit utilization of the visual semantics in motion forecasting can enhance its performance. Specifically, this work proposes ViRR(Visual Relation Reasoning), which aims to provide the prediction module with complex visual reasoning of relationships among scene agents. To achieve this, we construct a novel visual scene graph, where the pairwise visual relations are first aggregated as each agent’s node feature. Then, the relations of the nodes are learned via higher-order relation reasoning method, which leverages the consecutive powers of the graph adjacency matrix. As a result, the extracted complex visual interrelations between the scene agents enable precise forecasting and provide explainable reasons for the model prediction. The proposed module is fully differentiable and thus can be easily applied to any existing vision-based PnP networks. We evaluate the motion forecasting performance of ViRR with challenging nuScenes benchmark and demonstrate its high necessity.