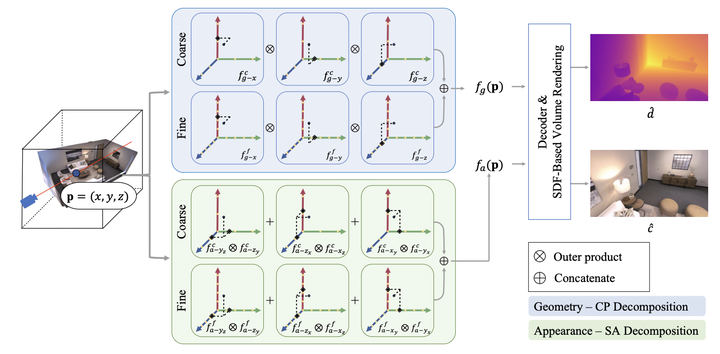
Abstract
Simultaneous Localization and Mapping (SLAM) has been crucial across various domains, including autonomous driving, mobile robotics, and mixed reality. Dense visual SLAM, leveraging RGB-D camera systems, offers advantages but faces challenges in achieving real-time performance, robustness, and scalability for large-scale scenes. Recent approaches utilizing neural implicit scene representations show promise but suffer from high computational costs and memory requirements. ESLAM introduced a plane-based tensor decomposition but still struggled with memory growth. Addressing these challenges, we propose a more efficient visual SLAM model, called LRSLAM, utilizing low-rank tensor decomposition methods. Our approach, leveraging the Six-axis and CP decompositions, achieves better convergence rates, memory efficiency, and reconstruction/localization quality than existing state-of-the-art approaches. Evaluation across diverse indoor RGB-D datasets demonstrates LRSLAM’s superior performance in terms of parameter efficiency, processing time, and accuracy, retaining reconstruction and localization quality. Our code will be publicly available upon publication.