Abstract
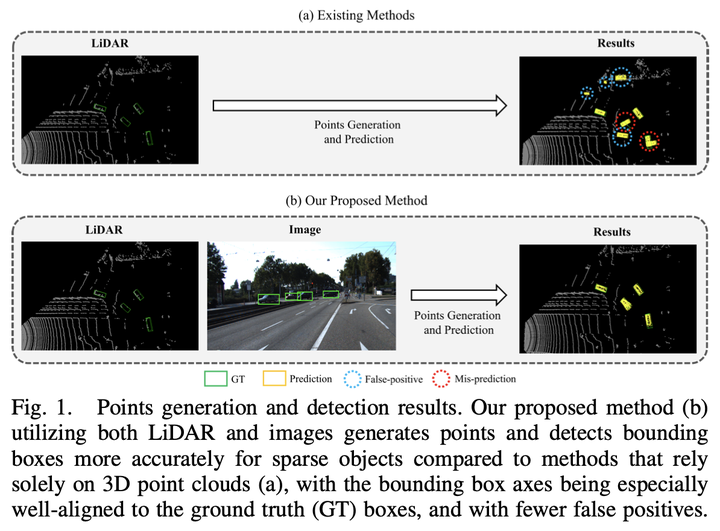
Accurately detecting objects at long distances remains a critical challenge in 3D object detection when relying solely on LiDAR sensors due to the inherent limitations of data sparsity. To address this issue, we propose the LiDAR-Camera Augmentation Network (LCANet), a novel framework that reconstructs LiDAR point cloud data by fusing 2D image features, which contain rich semantic information, generating additional points to improve detection accuracy. LCANet fuses data from LiDAR sensors and cameras by projecting image features into the 3D space, integrating semantic information into the point cloud data. This fused data is then encoded to produce 3D features that contain both semantic and spatial information, which are further refined to reconstruct final points before bounding box prediction. This fusion effectively compensates for LiDAR’s weakness in detecting objects at long distances, which are often represented by sparse points. Additionally, due to the sparsity of many objects in the original dataset, which makes effective supervision for point generation challenging, we employ a point cloud completion network to create a complete point cloud dataset that supervises the generation of dense point clouds in our network. Extensive experiments on the KITTI and Waymo datasets demonstrate that LCANet significantly outperforms existing models, particularly in detecting sparse and distant objects.